Train the Trainer workshop: Best practices for Writing FAIR and Reproducible Code

On the 24th and 25th June, 4TU.ResearchData’s FAIR and Reproducible Code Community Working Group conducted an online ‘Train the Trainer’ workshop for the data stewards and other research data management support professionals from 4TU partner institutions to learn best practices for writing FAIR and Reproducible software code.
The idea of this workshop was for experienced group members to teach others best practices for writing and managing code. The aim was for learners to gain the necessary skills to provide advice and develop similar training for researchers within their own institutions.
The planning phase

In April, a pre-workshop survey was completed by the data stewards to identify their needs, goals and expectations of the workshop.
From this survey, we identified five instructors and helpers: Heather Andews, Nicolas Dintzner, Santosh Ilamparuthi, José Urra Llanusa and Eirini Zormpa; and, nine learners: Marianna Avetisyan, Connie Clare, Simone Fricke, Paula Martinez Lavanchy, Zafer Özturk, Diana Popa, Phuong Truong, Yasemin Türkyilmaz van der Velden and Qian Zhang.
Before the workshop, learners had to follow preparation instructions to…
- Download software code (see Heather’s Python code for example)
- Become familiar with using the command line (terminal), and
- Install software packages (Git, Pip using Miniconda and GitHub).
The ‘Train the trainer’ workshop
Based on the pre-workshop survey results, the workshop training material was adapted from the ‘Best Practices in Writing Reproducible Code’ course developed by Barbara Vreede and colleagues from Utrecht University.
The workshop was delivered during two consecutive afternoon sessions to showcase best practices for writing and managing code in Python and R programming languages.

Instructors Nicolas Dintzner and José Urra Llanusa structured the course material using ‘Books with Jupyter’ to provide a clear overview of the workshop aims, preparatory instructions and agenda.
The workshop was conducted in a ‘flipped classroom’ format which required learners to undertake various code management exercises before the sessions and, then, work on live problem-solving during the sessions. We hosted different breakout sessions for R and Python in which learners could attempt and then discuss the exercises in their preferred programming language as a group.
Day 1
| 12:00 | Session zero: Last minute setup/environment fix for those who didn’t manage to install everything. | All |
| 13:00 | Welcome and Introduction | Connie & Nicolas |
| 13:15 | Project structure & Git: Questions | Heather |
| 13:30 | Project structure & Git: Breakout exercises | Heather & Eirini |
| 13:45 | Version control with Git: Questions | Heather |
| 14:00 | Version control with Git: Breakout exercises | Heather & Nicolas |
| 14:15 | Publication and Licensing: Questions | Santosh |
| 14:30 | Break | All |
| 14:45 | Code readability: Questions | Nicolas |
| 14:55 | Code readability: Breakout exercises | Nicolas |
| 15:15 | Code reusability: Questions | Nicolas |
| 15:25 | Code reusability: Exercise | Nicolas |
| 15:45 | Break | All |
| 16:00 | Code robustness: Questions | Nicolas |
| 16:15 | Code robustness: Demonstration | Nicolas |
| 16:35 | Q&A: General Discussion | All |
| 16:45 | End | All |
Day 2
| 13:00 | Q&A: Day 1 review | All |
| 13:10 | Comments and Docstring: Questions | Eirini |
| 13:25 | Comments and Docstring: Breakout exercise | Eirini |
| 13:45 | README: Questions | Eirini |
| 13:55 | README: Breakout exercise | Eirini |
| 14:15 | Break | All |
| 14:30 | Dependencies: Questions | Heather |
| 14:45 | Dependencies: Breakout exercise | Heather and Nicolas |
| 15:00 | Binder: Questions | Eirini |
| 15:15 | Archiving: Questions | Santosh |
| 15:30 | Break | All |
| 15:45 | Q&A: General Discussion | All |
| 16:00 | End | All |
Post-workshop reflections
A post-workshop survey was completed by five learners who participated in the workshop to gather feedback about the duration, preparation, format, structure and content covered.
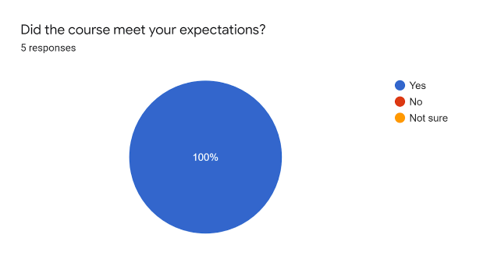
The responses demonstrated that the workshop met expectations, but that perhaps the duration could have been longer to accommodate the large volume of material covered in the live sessions.

The respondents spent a varied amount of time preparing for the workshop (from <1 hour to 4 hours). They reported that the preparatory steps could have been more explicit to indicate the time required for each exercise since this was generally underestimated by the learners.

In general, the respondents believed the balance between self-study and live sessions during the ‘flipped classroom’ format to be ‘about right’, however, some would prefer to have more live sessions to work through the material together and live sessions could be longer.
One learner reported that they would have preferred to undertake the exercises with others in small groups and with the instructors/helpers available to assist and answer questions during the process. They stated that it was frustrating to encounter difficulties during an exercise and to have to wait for the live session to troubleshoot the problem.


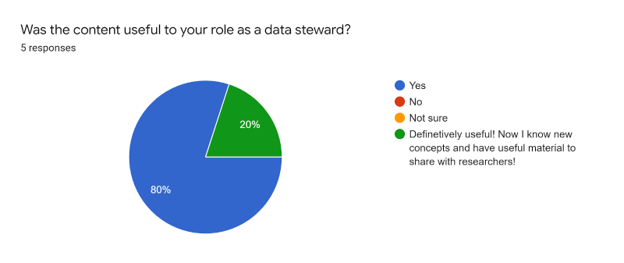
In general, respondents believed that the workshop content was useful to the role of a data steward and that the training materials serve as a useful resource to be shared with researchers.
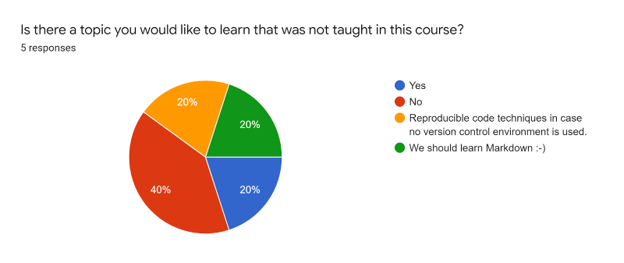
In particular, the ‘project set-up’ and ‘Q&A: General Discussion’ were voted the most useful sessions during the workshop. Respondents indicated that future topics of interest for the group to learn are how to use markdown, and how to write FAIR and reproducible code when no version control environment is used.

We asked the learners to tell us what they liked about the course… Here’s what they said:
- “Great materials and great and knowledgeable instructors.”
- “The diverse content.”
- “I liked the group a lot and how knowledgeable our instructors are.”
- “The team, the atmosphere, everything!”
- “Knowledgeable instructors who gave clear answers to all our questions; received a lot of useful information; nice exercises”.
- “I would like to do more than that but I do not have the time capacity or background to be able to run these workshops in my faculty on my own.
- “I will have to go through the materials at a slower pace”
- “It would be great to have this course as an online module with a question hour I think! That would make it easy to implement and I think it would work for the target group!”
The next steps…
We’re now taking a break and some time to reflect over the summer. In September, we’ll reconvene for our monthly meetings to discuss future directions and deliverables for the FAIR ad Reproducible working group. More to follow towards the end of the year!

Written by Heather Andrews, Connie Clare, Santosh Ilamparuthi, José Urra Llanusa and Eirini Zormpa
Images by Peggy_Marco on Pixabay