


Giordano Lipari is a consultant and researcher in computational and environmental hydrodynamics at Watermotion | Waterbeweging. After hearing that his data collection in 4TU.ResearchData has already been viewed more than 2,000 times, our community manager, Connie Clare, sat down with Giordano to discuss his experience.
Tell us something about your data collection. The datasets within have been downloaded 3,500 times since their deposit last April.
We published a 735GB large collection, ‘High-resolution SPH simulations of a 2D dam-break flow against a vertical wall’, which comprises 1650 data files from high-resolution simulations of fluid flows. This data has been shared as a tail of a postdoctoral project at TU Delft where I worked with Kees Vuik at the Delft Institute of Applied Mathematics to audit computer programs to simulate such flows.
What are simulations of fluid flows and what are their real-world applications?
A computer simulation basically consists of four ingredients: going backwards in the workflow, you give a piece of hardware a piece of software that implements the mathematics that expresses, in our case, some physics. I was studying a methodology called smoothed particle hydrodynamics and was interested in the impact of water on objects, or vice versa. These simulations model real-word problems, such as waves hitting ships, dykes or breakwaters, where water could damage structures.

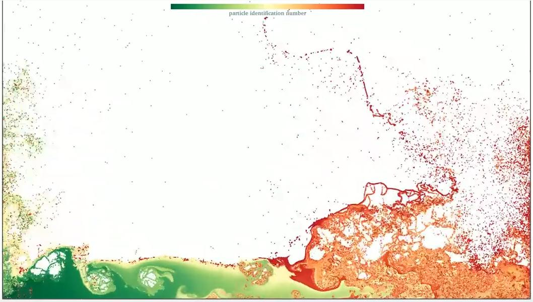

Why do these simulations produce massive data?
Researchers studying hydrodynamics ideally want to track the motion of water down to the very smallest particles of fluid the flow consists of. Whilst this level of description is unachievable for general purposes, the quest for it is a motivator for researchers since finer details provide more insight into fluid flow behaviour. The more refined the simulation, the longer the computing time and the larger the data files generated.
How did you run the simulations?
We had fast Graphics Processing Units (GPUs) at our disposal. We could describe the motion of water impacts with up to 100 million particles and produce 1TB worth of data in just five days. Collecting this large amount of data means that all tasks in an ordinary research workflow scale up with the problem size accordingly, with new challenges arising. For example, data storage can fill up fairly quickly before you’ve had time to analyse the data. This is a typical issue associated with high-performance computing.
Why did you decide to publish your data and software code?
The datasets are not associated with a published paper but we had started by sharing animations of high-resolution flow simulations via our YouTube channel. Then, we thought we should share the underlying data and code as it offers others the opportunity to look into precomputed high-resolution simulations. The simulation data we produced is highly valuable for many scholars and practitioners since the hardware we had is hard to afford for most. We also used an open-source flow solver and could include the code in the collection, so that anyone can reproduce the results if so wished. In this way, we demonstrate a prime example of open science practice.


carrying floating-point operations in double precision at a rate of 4 TFLOPS.
Since becoming a data champion at TU Delft, I was also aware of the university’s research data framework policy. This has been an inspiration to publish our simulations in a way that makes them FAIR (Findable, Accessible, Interoperable and Reusable). As researchers from a partner organisation we could deposit up to 1TB free of charge in the 4TU.ResearchData repository. My faculty data steward, Santosh Ilamparuthi, provided useful tips for how to get started and the curators from 4TU.ResearchData, Jan van der Heul and Egbert Gramsbergen, supported our initiative throughout the upload stage.
Who do you expect to be interested in your data collection?
The flow we selected for deposit has a benchmark value for our specialist community. I envisage that researchers using the same methodology as ours are interested in exploring our data collection. Researchers using other methodologies may also be interested in comparing results. In addition, looking into precomputed data can have educational value for students.
What’s more, high-performance computing and large datasets bring challenges beyond the discipline that stimulates a study. For example, due to the granularity of the high-resolution images, the datasets may also appeal to researchers and developers from computer graphics to test and improve their tools for rendering complex visualisations.
You have published 1,650 data files. How have you organised these in the repository to ensure they invite exploration?
The files are many and large. Without organisation, navigating more than a thousand large descriptions of fluid flows can easily turn a user’s initial curiosity into discouragement and uninterest. You cannot expect people to download such large amounts of data in bulk and sift through the numerous files. This would be too time and labour intensive. Regarding the FAIR data principles, ‘accessibility’ does not scale well with the deposit size. It was, therefore, important to prepare the data and organise it appropriately before publication.
The best way to do this was by creating a data collection comprising four datasets containing the core information, plus an entry dataset which serves as a one-stop catalogue of the collection’s contents, including visualisations of the raw data. The entry dataset allows users to form their idea of the simulations, navigate the collection and select data files of choice. The data files have not been bundled in archives and are in a highly compressed format. So they can be downloaded individually in a tolerable transfer time using a moderate bandwidth.
Finally, besides the standard README files, we also wrote a commentary that caters for a variety of approaches and levels of expertise. It has been important to inform viewers about our rationale and methodology with additional descriptive documentation. . The commentary explains why and how we created so much data, where to find data files, and suggests for inspiration how the data can be used. The commentary should allow viewers to decide which datasets are valuable to them. Organising the voluminous data collection in this way provides a well-marked path for viewers to confidently dive into the details.
Giordano, thank you for taking the time to share your considerations for publishing large datasets. We’re pleased that your data collection has become a highly accessed resource. Do you have any final thoughts to share with us?
Thank you, Connie. Accessibility is important for any dataset. However, when depositing large datasets in particular, depositors need to compensate for the hurdles that arise from their sheer size. Facilitating the access itself does not guarantee many data downloads, still is a necessary part of effective research data management. All the preparation requires careful design and some extra effort but is worth it! The items within our collection have been downloaded an average 11 times a day in the last eleven months.
Such usage metrics are a great success, demonstrating that viewers have engaged with the collection, large as it is, and decided to explore the parts relevant for them. This alone makes the effort of sharing invaluable.
“Accessibility is important for any dataset. However, when depositing large datasets in particular, depositors need to compensate for the hurdles that arise from their sheer size. Facilitating the access itself does not guarantee many data downloads, still is a necessary part of effective research data management.”
— Giordano Lipari
Co-authored and edited by: Giordano Lipari and Connie Clare